Your agent works in the demo. Does it work in production?
The Agent Reliability Platform is how Quabyt takes agentic AI systems past the pilot wall. Versioned evals, layered guardrails, OpenTelemetry tracing, and per-request cost controls, delivered as a fixed-price audit, a hardening sprint, or an ongoing retainer.
The pilot wall
Why most agents stall before production
Almost every team we audit has shipped a v1 agent. Almost none of them can answer these four questions with evidence.
When the agent gets it wrong, can you tell?
No eval suite, no regression detection. Bad outputs surface as customer complaints, not CI failures.
When a prompt or model changes, what breaks?
Prompts are edited in production. Model providers ship silent upgrades. Nobody knows what regressed until somebody notices.
Where did this month's $40K go?
Token spend doubled and nobody can point at the request types, tenants, or model calls responsible.
When somebody jailbreaks it, what happens?
No input validation, no tool-use policy, no audit log. The blast radius is whatever an attacker is willing to test.
What we ship
Four reliability primitives, wired into your agent
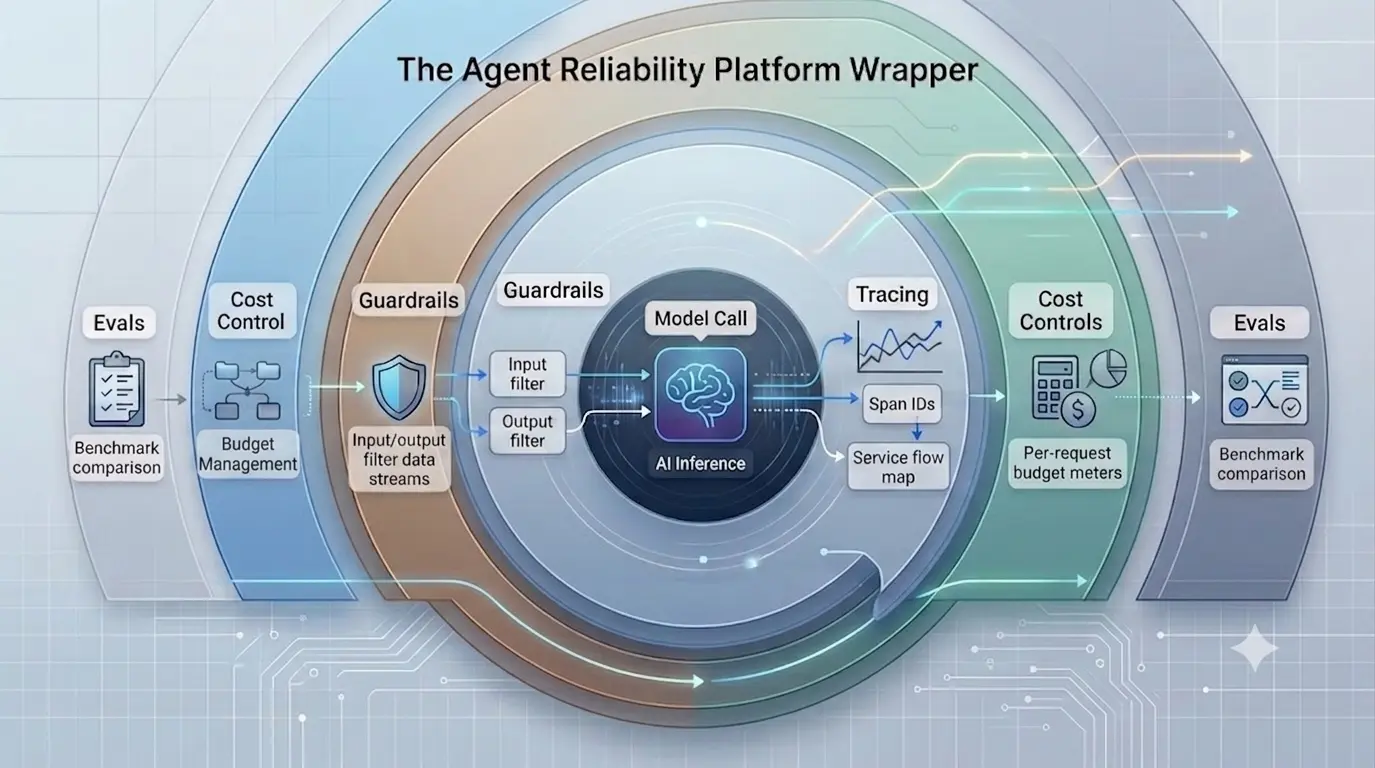
Every model call routes through one wrapper. That wrapper checks inputs, meters cost, emits traces, validates outputs, and records the run for evals. Same shape across LangGraph, CrewAI, Claude Agent SDK, OpenAI Agents SDK.
Golden, adversarial, and synthetic suites. LLM-judge scorers with calibration. CI blocks merges that regress beyond your threshold. Pushed to Langfuse or Braintrust; we're vendor-agnostic.
Input PII detection and prompt-injection filtering. Output schema validation and toxicity check. Tool-use policy with per-role allowlists, rate limits, and human-in-the-loop on high-stakes actions.
Every model call, tool call, and guardrail decision emits an OTel span using gen_ai.* semantic conventions. Plugs into Langfuse, Datadog, Honeycomb, or any OTel backend.
Token + dollar accounting attributed to tenant, feature, and model. Hard or soft budgets per request. Cheap-first model routing with confidence escalation — typically cuts spend 40–70%.
The rubric
Score your own system against the Quabyt Reliability Scorecard
Eval coverage
Versioned golden + adversarial datasets. Per-step evals for multi-step agents. Production sampling feeds back into the suite.
Regression detection
Evals run in CI on every change to prompts, tools, or models. Merges blocked on threshold regression. Trend over time, not just pass/fail.
Guardrails
Input PII + prompt-injection. Output schema + safety. Tool-use policy per role. Every trip logged and reviewable.
Observability
OTel gen_ai.* spans. Tenant/session correlation. Retention long enough to investigate. Single pane of glass with cloud telemetry.
Cost controls
Per-request token + dollar accounting. Cost attributed to tenant / feature / model. Budgets enforced. Cheap-first routing where applicable.
Failure-mode mapping
Documented failure-mode list with detection and mitigation. Post-incident reviews update the list. Each mode has an owner.
Security & data handling
No PII or secrets in prompts unless redacted. Least-privilege IAM for tools. Audit log of agent actions. Prompt-injection treated as a real threat.
Deployment & operations
Prompts and tool configs version-controlled. Feature flags or staged rollouts. On-call runbook for AI incidents. Rollback that doesn't require redeploying the world.
Three ways to engage
Step 1: Reliability Audit — 2 weeks, fixed price
We score your agent across the 8 dimensions, build an adversarial eval set targeting your specific failure modes, and deliver a prioritized remediation roadmap with a live demo of the worst findings. The output is a decision artifact you own.
Step 2: Reliability Hardening — 6–10 weeks, fixed price
Implementation. We install the eval harness, guardrails, OTel tracing, and cost controls into your codebase. CI gates wired up. Operator runbook delivered. Your team learns the patterns alongside us so it's yours to evolve.
Step 3: Reliability Retainer — monthly
New evals as failure modes emerge. Quarterly red-team refresh. Model migration support via trace replay (Claude 4.6→4.7, GPT-5→next). Cost optimization passes. On-call escalation for AI-specific incidents.
No lock-in
Vendor-agnostic by design
The platform sits on open standards. You keep optionality on models, observability backends, and eval tooling.
LangGraph, CrewAI, OpenAI Agents SDK, Claude Agent SDK, LangChain. Reference implementation in LangGraph; ports available.
Langfuse (self-hostable open source), Braintrust (hosted). Pluggable adapter interface — swap without re-instrumenting.
OpenTelemetry gen_ai.* semantic conventions as the wire format. Exports to Langfuse, Datadog, Honeycomb, Grafana Tempo, anything OTel-compatible.
OpenAI, Anthropic, Google, AWS Bedrock, Azure OpenAI Service. Open-weight models via vLLM or provider-managed endpoints.
Microsoft Presidio for PII, Pydantic for schemas, pluggable detectors for toxicity (Llama Guard, Perspective, Detoxify). Custom rules in YAML.
Python primary, with TypeScript clients for frontends. Runs anywhere your agent runs — Kubernetes, Lambda, Cloud Run, bare VMs.
FAQs
Common questions
How is this different from Braintrust, Langfuse, or LangSmith?
Those are excellent tools — we use them. The reliability problem isn't a missing tool; it's missing engineering. Most teams have access to these platforms and still can't answer the four questions on this page. We bring the rigor and the integration work, not another SaaS.
Do you replace our existing agent framework?
No. The platform wraps the model calls inside whatever framework you chose. We have a reference implementation in LangGraph, but we've deployed the same patterns on CrewAI, Claude Agent SDK, OpenAI Agents SDK, and custom orchestrators.
Is the Audit a sales call?
No. It's a paid, fixed-price engagement that produces a real artifact — the scorecard, the risk register, the remediation roadmap, and the adversarial eval set we built against your agent. You keep all of it whether or not we work together further.
What does a Hardening engagement actually deliver?
Code, in your repository. Eval harness, guardrails layer, OTel tracing, cost controls. CI gates configured. Operator runbook documented. Your team works alongside ours so the patterns stay maintainable after we leave.
Do we have to use Langfuse?
No. Langfuse is our default because it's open source and self-hostable, which matches our no-lock-in posture. Braintrust is a one-line adapter swap. Any OTel-compatible backend works for tracing.
How quickly can you start?
An Audit typically starts within 1–2 weeks of contract signature. Hardening engagements follow the Audit and are scoped from the roadmap it produces. Retainers begin once Hardening is complete.
Will you sign an NDA before reviewing our code?
Yes. We sign before any code access. Production traces containing PII are handled under a separate data-handling addendum if needed.
What if our agent is on AWS Bedrock / Azure / GCP?
All three are supported. Our case studies include Bedrock Agents (LangGraph + Langfuse), Azure (Document Intelligence + Functions), and Gemini Enterprise Agent Platform / Google ADK deployments. Multi-cloud is a core Quabyt strength, not an afterthought.
Run the scorecard on your agent
Most teams discover their score is 1–2 points below where they thought it was. A two-week Reliability Audit answers the question with evidence — and gives you a roadmap you can act on whether or not we're the team that implements it.