LLM Fine-tuning vs. RAG: Choosing the Right Approach for Custom AI
Dive deep into the practical differences between fine-tuning Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to make informed strategic decisions for your AI systems.
As AI practitioners, we know that harnessing the power of Large Language Models (LLMs) like GPT, Claude, or Llama often requires moving beyond their impressive, yet generic, off-the-shelf capabilities. Foundational models are trained on vast web-scale data, but they inherently lack the specialized knowledge, nuanced understanding of specific domains, or the precise brand voice your application demands. Relying solely on base models often leads to outputs that feel bland, occasionally drift into factual inaccuracies (the dreaded hallucinations), or simply fail to capture the specific context vital for real-world business value.
To truly differentiate and build robust AI solutions, customization isn’t just an option; it’s essential. The core challenge lies in effectively tailoring these powerful models. Two dominant paradigms have emerged: LLM Fine-tuning and Retrieval-Augmented Generation (RAG). While both aim to inject specific knowledge and control LLM behavior, their underlying mechanisms, strengths, trade-offs, and optimal use cases differ significantly. Getting this choice right is fundamental to architecting effective AI systems and maximizing ROI.
What is LLM Fine-tuning? Unpacking the Core Idea
At its heart, LLM Fine-tuning involves taking a pre-trained foundational model – one that already possesses broad language understanding – and continuing its training process, but this time on a curated, smaller dataset tailored to your specific domain or task. Think of it as specialized postgraduate education for the LLM. This process subtly adjusts the model’s internal parameters (its weights and biases) to absorb new knowledge patterns, adopt a specific style, or become proficient in tasks directly represented in the fine-tuning data.
It’s less about teaching the model brand new facts (though that happens) and more about teaching it how to behave or how to apply its knowledge within your specific context.
Fig 1: Fine-tuning leverages a pre-trained model’s foundation, adapting it with task-specific data.
The Workflow: From Data to Deployment
- Curating the Training Corpus: This is often the most critical step. You need a high-quality dataset representing the target domain or desired behavior. For instruction-following models, this typically involves prompt-response pairs (e.g.,
{"instruction": "Summarize this legal clause:", "input": "<clause text>", "output": "<concise summary>"}). The quality and relevance of this data directly impact the fine-tuned model’s success. - Training Phase: Choose a suitable pre-trained base model (considering size, capabilities, and licensing). The actual training usually involves techniques like Parameter-Efficient Fine-Tuning (PEFT), such as LoRA or QLoRA, to modify only a small subset of the model’s parameters. This significantly reduces the computational cost (GPU memory and time) compared to full fine-tuning, making it feasible for many organizations. Training typically runs for a few epochs over the curated dataset.
- Rigorous Evaluation: Before deploying, assess the fine-tuned model against a hold-out validation set using relevant metrics (e.g., ROUGE for summarization, accuracy for classification, or qualitative human evaluation for style).
- Deployment & Inference: Integrate the fine-tuned model (often just the base model plus small adapter weights if using PEFT) into your application.
Conceptual Code Example (Fine-tuning with QLoRA-style approach)
# NOTE: This is a simplified conceptual example.# Actual implementation would require proper error handling, logging, etc.
import osimport torchfrom datasets import load_datasetfrom transformers import ( AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, TrainingArguments)from peft import LoraConfig, get_peft_modelfrom trl import SFTTrainer
# 1. Define the base model and quantization settingsmodel_id = "meta-llama/Llama-2-7b-hf" # Example base modelbnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.float16,)
# 2. Load the base model with quantizationtokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_token # Set padding token
model = AutoModelForCausalLM.from_pretrained( model_id, quantization_config=bnb_config, device_map="auto", trust_remote_code=True,)
# 3. Configure LoRA adapters for efficient fine-tuninglora_config = LoraConfig( r=16, # Rank of the update matrices lora_alpha=32, # Scaling factor lora_dropout=0.05, # Dropout probability bias="none", task_type="CAUSAL_LM", target_modules=["q_proj", "v_proj"] # Attention layers to fine-tune)
# 4. Apply LoRA adapters to the modelmodel = get_peft_model(model, lora_config)
# 5. Prepare your custom dataset# This is a simplified example - you'd typically have your own datasetdata = load_dataset("json", data_files="your_custom_data.json")
# 6. Configure training argumentstraining_args = TrainingArguments( output_dir="./results", num_train_epochs=3, per_device_train_batch_size=4, gradient_accumulation_steps=4, learning_rate=2e-4, weight_decay=0.001, logging_steps=10, save_steps=100, save_total_limit=3, fp16=True,)
# 7. Initialize the SFT Trainertrainer = SFTTrainer( model=model, args=training_args, train_dataset=data["train"], tokenizer=tokenizer, max_seq_length=512, packing=True, # Efficient packing of sequences)
# 8. Train the modeltry: trainer.train() print("Fine-tuning completed successfully!")
# 9. Save the fine-tuned model (just the adapter weights) model.save_pretrained("./fine_tuned_adapter") tokenizer.save_pretrained("./fine_tuned_adapter")
except Exception as e: print(f"An error occurred during training: {e}") # model.save_pretrained("./fine_tuned_model") # Save the adapterPros: Why Consider Fine-tuning?
- Deep Behavioral Adaptation: Fine-tuning excels at embedding specific styles, tones, personas, or complex instruction-following capabilities directly into the model’s parameters. It’s the go-to for teaching the model how to respond, not just what information to use.
- Enhanced Performance on Niche Tasks: For highly specialized tasks (e.g., recognizing specific entity types in legal text, adopting a unique brand voice), fine-tuning can often yield superior performance compared to prompting a general model, as the required knowledge becomes intrinsically part of the model.
- Reduced Inference Costs: Once fine-tuned, the model can generate appropriate responses without needing lengthy context windows filled with examples or instructions, potentially reducing token usage and inference costs.
Cons: The Trade-offs and Challenges
- Significant Data Curation Effort: The success of fine-tuning hinges heavily on the quality and quantity of the training data. Creating a robust, diverse, and representative dataset (often thousands of high-quality examples) is frequently the most resource-intensive part of the process.
- Computational Resources & Expertise: While PEFT methods like QLoRA have drastically lowered the barrier, fine-tuning still requires access to capable GPUs (often cloud-based) and expertise in MLOps for training, evaluation, and deployment.
- Risk of Catastrophic Forgetting: A known challenge where the model, while specializing, might lose some of its original general capabilities or proficiency in tasks not covered by the fine-tuning data.
- Hallucination Potential Remains: While fine-tuning can reduce hallucinations within its specialized domain, it doesn’t eliminate them. The model can still confabulate if prompted outside its area of expertise or if the fine-tuning data itself contained subtle biases or inaccuracies.
Use Cases
- Adapting a model to a specific writing style or brand voice.
- Improving performance on niche classification or summarization tasks.
- Creating specialized assistants with consistent behavior patterns.
- Developing models that require deep understanding of specific domains (e.g., medical, legal, financial) where the knowledge is relatively stable.
What is RAG? The Alternative Approach
Retrieval-Augmented Generation (RAG) takes a fundamentally different approach. Rather than modifying the model itself, RAG keeps the base LLM unchanged but dynamically augments its inputs with relevant information retrieved from an external knowledge base at inference time. This creates a powerful combination: the general language capabilities of the base model plus the specific, up-to-date knowledge from your curated sources.
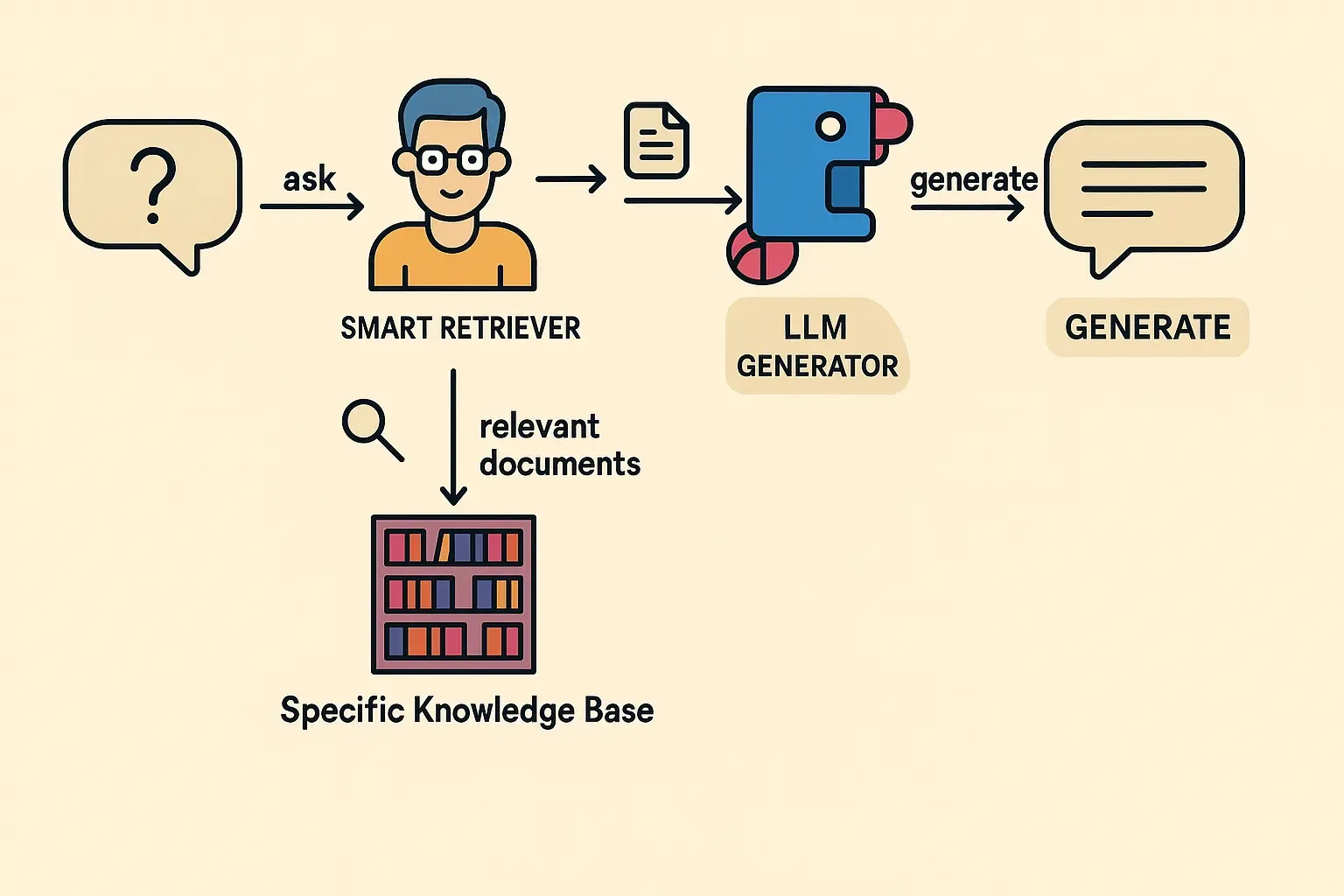
Fig 2: RAG first retrieves relevant documents, then feeds them as context to the LLM for generation.
The RAG Pipeline: Ingest, Retrieve, Generate
- Knowledge Base Preparation (Offline): Your external knowledge sources (PDFs, web pages, database entries, etc.) are processed, broken down into manageable chunks, and indexed, typically by generating vector embeddings for each chunk. These embeddings capture semantic meaning and are stored in a specialized vector database (like FAISS, ChromaDB, Pinecone, Weaviate). This indexing step allows for efficient similarity searches later.
- Retrieval (Online - at Query Time): When a user submits a query, the system first converts the query into an embedding and then searches the vector database to find the text chunks whose embeddings are most semantically similar to the query embedding.
- Prompt Construction (Online): The retrieved text chunks are then incorporated into a prompt template, typically as context for the LLM. This template often includes instructions on how to use the provided context.
- LLM Generation (Online): This augmented prompt, now rich with relevant external context, is sent to the base LLM. The LLM uses this context, combined with its general world knowledge, to generate a final, grounded response.
Conceptual Code Example (RAG with LangChain-style approach)
# NOTE: This is a simplified conceptual example.# Actual implementation would require proper error handling, logging, etc.
import osfrom langchain.document_loaders import PyPDFLoader, DirectoryLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.prompts import PromptTemplatefrom langchain.chains import RetrievalQA
# 1. Load Documents (Knowledge Base Preparation)try: # Load PDF documents from a directory loader = DirectoryLoader("./documents/", glob="**/*.pdf", loader_cls=PyPDFLoader) documents = loader.load() print(f"Loaded {len(documents)} document pages")
# 2. Split documents into chunks text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, length_function=len, ) chunks = text_splitter.split_documents(documents) print(f"Split into {len(chunks)} chunks")
# 3. Create embeddings and store in vector database embedding_function = OpenAIEmbeddings() # Requires OPENAI_API_KEY in env vectorstore = Chroma.from_documents( documents=chunks, embedding=embedding_function, persist_directory="./chroma_db" ) print("Vector database created and persisted")
# 4. Create a retriever retriever = vectorstore.as_retriever( search_type="similarity", search_kwargs={"k": 5} # Return top 5 most relevant chunks )
# 5. Create a custom prompt template template = """ You are a helpful assistant that answers questions based on the provided context.
Context: {context}
Question: {question}
Answer the question based on the context provided. If the answer cannot be determined from the context, say "I don't have enough information to answer this question."
Answer: """
prompt = PromptTemplate( template=template, input_variables=["context", "question"] )
# 6. Create the RAG chain llm = OpenAI(temperature=0) # Requires OPENAI_API_KEY in env
qa_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", # Simple approach that stuffs all retrieved docs into prompt retriever=retriever, chain_type_kwargs={"prompt": prompt} )
# 7. Example query query = "What are the key benefits of our product?" result = qa_chain.run(query) print(f"Query: {query}") print(f"Result: {result}")
except Exception as e: print(f"An error occurred during RAG execution: {e}")Key Differences Summarized: Fine-tuning vs. RAG
While both fine-tuning and RAG aim to augment LLMs with specific knowledge, their fundamental mechanisms dictate distinct characteristics in practice:
-
Knowledge Integration Point:
- Fine-tuning: Integrates knowledge during training by modifying the model’s parameters. The knowledge becomes an intrinsic part of the model’s reasoning process.
- RAG: Injects knowledge at inference time via external context retrieved dynamically. The base LLM’s parameters remain untouched.
-
Nature of Adaptation:
- Fine-tuning: Excels at teaching the model how to behave – adapting style, tone, persona, or complex task formats.
- RAG: Excels at providing the model what to know – supplying specific, up-to-date factual information.
-
Data Requirements & Preparation:
- Fine-tuning: Requires curated, often structured, high-quality datasets (e.g., instruction-response pairs). Data quality heavily dictates model performance. Significant upfront effort in data preparation and annotation.
- RAG: Leverages existing (often unstructured) document corpora. Primary effort lies in establishing robust ingestion, chunking, embedding, and indexing pipelines for the knowledge base.
-
Cost Profile (Compute & Maintenance):
- Fine-tuning: High upfront compute cost for training (though reduced by PEFT). Ongoing cost for retraining to update knowledge. Inference cost might be lower per call if the model isn’t significantly larger.
- RAG: Lower initial training cost (uses base LLM). Costs shift towards maintaining the retrieval infrastructure (vector DB, indexing) and higher per-inference cost due to the retrieval step.
-
Knowledge Freshness:
- Fine-tuning: Knowledge is static, reflecting the state of the data at the time of training. Updates require full retraining cycles.
- RAG: Knowledge is dynamic. Updates involve simply refreshing the external knowledge base, offering near real-time information access.
-
Hallucination Mitigation:
- Fine-tuning: Can reduce domain-specific hallucinations by reinforcing correct patterns from training data, but doesn’t eliminate the inherent risk, especially outside the fine-tuned scope.
- RAG: Offers stronger hallucination control by grounding responses directly in retrieved evidence. Easier to trace information provenance.
Strategic Decision Framework: When to Choose Fine-tuning?
From a system design perspective, fine-tuning becomes the strategically sound choice when:
- Behavioral Shaping is Primary: The core requirement is to instill a specific persona, writing style, tone, or complex, nuanced instruction-following capability that’s difficult to reliably elicit through prompting alone.
- Implicit Domain Knowledge: The task requires understanding deep, implicit patterns, jargon, or relationships within a narrow domain that aren’t easily captured in discrete, retrievable text chunks.
- Inference Latency is Non-Negotiable: The application demands the absolute lowest possible latency per inference, and the overhead of RAG’s retrieval step is prohibitive (assuming the fine-tuned model inference itself remains sufficiently fast).
- High-Quality Training Data is Available: You possess or can feasibly create a sufficiently large (hundreds to thousands of examples) and high-quality dataset that accurately represents the desired outputs or behaviors.
- Knowledge Base is Relatively Stable: The underlying knowledge required for the task doesn’t change frequently, making the cost and effort of periodic retraining acceptable.
Strategic Decision Framework: When to Lean Towards RAG?
RAG often emerges as the more pragmatic and effective architecture when:
- Dynamic, Evolving Knowledge is Crucial: The application must operate on information that changes frequently (e.g., real-time inventory, current events, updated policies, rapidly evolving technical documentation).
- Minimizing Hallucinations is Paramount: Factual accuracy, grounded in verifiable external sources, is a critical requirement for trust and reliability (e.g., enterprise Q&A, financial reporting tools, medical information systems).
- Source Attribution & Transparency: The ability to cite the specific sources used for generation is necessary for compliance, verification, or user trust.
- Leveraging Existing Document Assets: You have a wealth of existing documents, databases, or APIs that contain the necessary knowledge, even if curating a fine-tuning dataset is infeasible.
- Faster Time-to-Value & Iteration: RAG often allows for quicker deployment and iteration, as knowledge updates don’t require retraining the core LLM. Focus shifts to optimizing the retrieval pipeline.
Hybrid Architectures: The Best of Both Worlds?
Crucially, fine-tuning and RAG are not mutually exclusive; sophisticated systems often blend both techniques. Common hybrid patterns include:
- Fine-tune for Task/Style, RAG for Knowledge: Fine-tune a base LLM to master a specific task format (e.g., structured report generation) or adopt a desired persona, then use RAG at inference time to inject current, factual data from an external knowledge base. This leverages fine-tuning for how to respond and RAG for what to base the response on.
- Fine-tuning the Retriever: Instead of fine-tuning the generator LLM, you might fine-tune the embedding model used in the RAG retrieval step. This can make the retriever more adept at finding relevant information within your specific domain’s unique terminology or concepts.
- Fine-tuning for Query Rewriting: Fine-tune a smaller model specifically to refine user queries before they hit the RAG retriever, improving the relevance of retrieved documents.
While powerful, hybrid approaches inevitably introduce greater architectural complexity and require careful orchestration and end-to-end evaluation.
Conclusion: Architecting for Success
Choosing between LLM fine-tuning and RAG – or designing an effective hybrid – is a critical architectural decision. There’s no single ‘best’ answer; the optimal approach depends entirely on the specific requirements of your application, your data landscape, acceptable latency, tolerance for hallucinations, and available resources (both computational and human expertise).
- Prioritize fine-tuning when deeply embedding specific behaviors, styles, or niche knowledge patterns is the core objective, provided you can resource the data curation and training.
- Default to RAG when leveraging dynamic knowledge sources, maximizing factual grounding, and ensuring transparency are paramount, and you can build and maintain a robust retrieval pipeline.
- Explore hybrid models for complex scenarios demanding the nuanced strengths of both paradigms, acknowledging the increased system complexity.
A clear understanding of these trade-offs empowers technical leaders and practitioners to design and implement LLM solutions that are not just powerful, but also reliable, maintainable, and aligned with specific business outcomes. At Quabyt, we partner with organizations to navigate these strategic choices, architecting and implementing custom Generative AI solutions that deliver tangible value. Reach out to discuss how we can tailor an approach for your unique needs.