knowledgebase
chatbot
LLMs
AI
Democratizing Knowledge Across The Organization
Discover how LLM-powered chatbots can enable seamless access to organizational knowledgebases, enhancing productivity, and fostering a culture of collaborative learning and innovation within organizations

Share it:
The inability of employees to access the information they need, when they need it, is a problem that costs organizations time, money and competitive advantage. More often than not, the problem is that the knowledge is stuck in silos across the organization. We will not go into the governance aspects of the problem here, rather focus on technical implementation of the solution, governance will be the topic of another post. This article will demonstrate building a LLM powered chatbot that can help easy & widespread access to organizational knowledge base (KB).
Conversational AI has been around for a while now but with emergence and evolution of LLMs, we have what we would like to call Conversational AI on steroids.
What we will cover
- Review KB sources
- How to consolidate and make KB data searchable
- How to use LLMs to work against org KB data
- Building a chatbot interface for the LLM
Technologies/Tools
- Embeddings
- Vector databases
- LLM models
- Langchain
- Cohere
- ChromaDB
- Gradio
- Python
KB sources
Organizations typically have many departments and every department has its knowledge base which is disparate from other departments. While one department may have a wiki, the other maybe keeping word/pdf documents in a share. Developer documentations are converging towards readme (.md) files. While there maybe many other scenarios, lets address the three cases above. We will ingest data from word, pdf, md files. Most wikis support data export in one of the above file formats, if not, web scraping can be done using tools/platforms like apify or langchain’s WebBasedLoader.
Our goal is to enable semantic search on KB data. Unlike traditional keyword-based (lexical) search, which relies solely on matching specific words or phrases, semantic search focuses on the intent and context behind a query. It seeks to comprehend the semantics, or meaning, of the query and the content to deliver more contextually relevant results. First step towards implementing semantic search is to generate embeddings for the data and store the embeddings in a vector store/database. Let’s first understand what Embeddings are and why they are the lynchpin of LLM powered apps.
Embeddings
Humans comprehend language through words, while computers interpret information primarily using numerical representations. This is where embeddings play a crucial role - capturing the semantics and meaning of human-understandable concepts and translating them into machine-interpretable representations.
You Shall Know a Word by the Company It Keeps
John Rupert Firth
In machine learning, embeddings are a powerful technique that helps convert categorical data, like words, into numerical vectors. Imagine trying to teach a computer to understand the meaning (semantics) of words or categories like “apple” or “lion” or “car”. While humans grasp these concepts naturally, machines typically work with numbers. Embeddings bridge this gap by mapping each category to a unique vector in a continuous, lower-dimensional space. These vectors capture not only the category’s identity but also its relationships with other categories, making them invaluable for tasks like natural language processing, recommendation systems, and image analysis, where understanding the context and similarity between categories is crucial for accurate predictions.
Embeddings are often used to represent complex data types, such as images, text, or audio, in a way that machine learning algorithms can easily process. Below is a representation of how vectors are represented in a n-dimentional space, note the relationship vis-à-vis the proximity
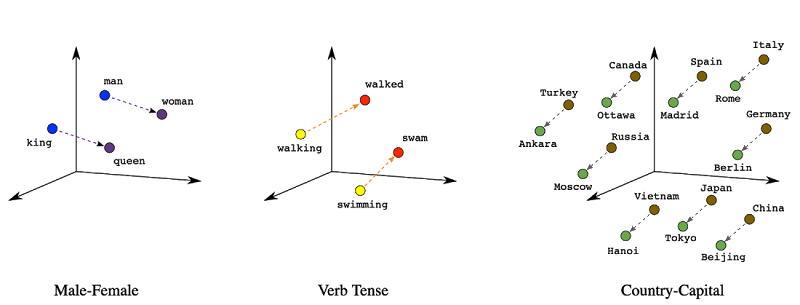
Detailed treatment of Embeddings is beyond the scope of this post, for an indepth look, check this blog.
In this article we will be dealing with word embeddings. There are many ML modles available to generate embeddings. SBERT evaluated list is a great place to choose a model to generate embeddings. One can also choose the model from MTEB Leaderboard.
Document Ingestion
The overall flow for document ingestion would look like in the below illustration. Some embedding models have limitations on the maximum length of input they can handle. Chunking allows you to break down longer texts into manageable segments that can be processed by the model. Chunking also provides other benefits like Memory Efficiency - chunking the text into smaller segments reduces the memory requirements thereby making the embedding generation more efficient; Context preservation - by breaking the text into smaller chunks, you can ensure that the local context of each segment is maintained. If you have custom code generating embeddings then its a good idea to count tokens to make sure model sequence limit is not exceeded, before sending corresponding text to the model

There are two ways to generate embeddings
- Call a hosted api like OpenAIEmbeddings, HuggingFace
- Run the embedding generation model locally
We will be using the 2nd option, saves network calls as well as moolah 😁
Enter chromadb, a vector store. Chroma’s api handles embedding generation & saving, so we don’t have to write much custom code. Although you can BYOE (Bring Your Own Embeddings), like from the OpenAI end point and save to chromadb.
Below code snippet shows how we load documents using langchain’s document loaders, full source code is available in the github repo provided at the end of this post. Collapsible sections are used to keep the code sections smallish, feel free to expand the collapsed lines
9 collapsed lines
import osimport argparsefrom typing import Listfrom tqdm import tqdmimport chromadbfrom chromadb.utils import embedding_functionsfrom langchain.schema import Documentfrom langchain.document_loaders import (UnstructuredMarkdownLoader, PyPDFLoader, UnstructuredWordDocumentLoader)from langchain.text_splitter import RecursiveCharacterTextSplitter
loaders = { ".pdf": PyPDFLoader, ".docx": UnstructuredWordDocumentLoader, ".md": UnstructuredMarkdownLoader,}
def load_documents_from_files(documents_directory: str) -> List[Document]: print("Loading docs...") documents = [] files = os.listdir(documents_directory) for file in tqdm(files): file_path = os.path.join(documents_directory, file) file_extension = os.path.splitext(file)[1]
if file_extension in loaders: loader_class = loaders[file_extension] loader = loader_class(file_path) docs = loader.load() chunks = chunk(docs) documents.extend(chunks) else: print(f"Loader for extension {file_extension} not found.") print(f"{len(documents)} documents loaded in memory") return documentsTaking a realistic usecase, we are processing sample knowledbases from three org departments - Finance, HR & Software Engineering. The data is taken from GitLab’s open handbook. Docs are included in the complementary github repo for this post. We have 3 types of documents - Pdf, Word and Markdown in our knowledge base. Using langchain’s loaders we load each file type and split them into chunks. We are using tqdm module to show a nice progress bar while processing files. Fun fact - the name tqdm is derived from the Arabic word “taqaddum”, which translates as “progress.”
Lets also review the code to save documents to ChromaDB:
def save_documents(documents: List[Document]) -> None: sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction( model_name="all-MiniLM-L12-v2" # Chroma uses all-MiniLM-L6-v2 by default. #Another good choice: e5-small-v2 ) # Instantiate a persistent chroma client in the persist_directory. chroma_client = chromadb.PersistentClient(path=persist_dir) collection = chroma_client.get_or_create_collection( name=collection_name, embedding_function=sentence_transformer_ef )8 collapsed lines
# Create ids from the current count # count = collection.count() # uncomment if you want to allow duplicate docs, e.g. multiple runs with same docs # print(f"Collection already contains {count} documents")
count = 0 # allows overwriting any existing docs with the same ids ids = [str(i) for i in range(count, count + len(documents))] metadatas = [documents[i].metadata for i in range(count, count + len(documents))]
# Load the documents in batches of 100 for i in tqdm(range(0, len(documents), 100), desc="Saving documents to database...", unit_scale=100): # documents is an object from langchain library, just pull out the page_content strings to save page_contents = [doc.page_content for doc in documents[i : i + 100]] collection.add( ids=ids[i : i + 100], documents=page_contents, metadatas=metadatas[i : i + 100], )
new_count = collection.count() print(f"Added {new_count - count} documents")Note that we are using a custom SentenceTransformer model here “all-MiniLM-L12-v2” instead of ChromaDB’s default “all-MiniLM-L6-v2” (as of this writing). This is to illustrate use of custom models for generating embeddings, however the default model works great too. Refer again to SBERT list & MTEB leaderboard to pick another model, if you prefer.
Next, we create a persistent cromadb client providing the persist_dir, location to save state between sessions. Chroma provides two clients for development and testing - EphemeralClient & PersistentClient. For production use, its recommended to use HttpClient with Chroma server running separately (like in a docker container). Finally we get or create the collection and prepare ids, metadatas and page_contents from documents list to bulk add to chromadb in batches of 100 for performance.
At this point the documents and associated embeddings are stored in ChromaDB collection. We can now use ChromaDB’s API to search, browse and explore the knowledge base programmatically. If you want to look at what is saved in the database (sqlite is what chroma uses), you can do so in VS Code with an extension like SQLTools, which allows managing multiple databases right from VS Code. Check docs for sqlite with SQL Tools.
If we perform the semantic search against the vector database the underlying flow would be like shown below
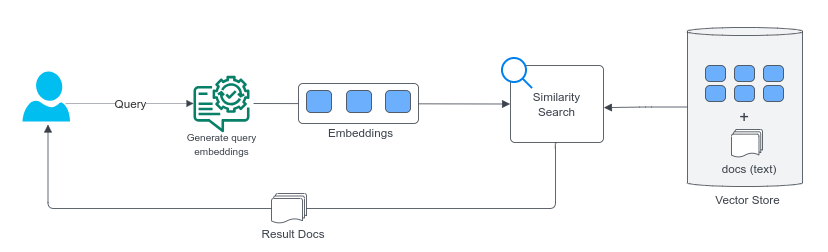
This approach would just return nearest docs/fragments verbatim without much of the semantics necessary for human consumption. We need additional NLP capabilities to make the results more useful. LLMs to the rescue.
Beyond simple vector search
LLMs add a layer of intelligence on top of basic vector search to transform retrieved results into natural language outputs that are more tailored, coherent and conversational for the end user. Some ways LLMs can enhance a knowledge retrieval system like ours:
Paraphrasing and summarization: LLMs can take the extracted document snippets from vector search and paraphrase or summarize them into more concise, coherent snippets for the end user. This makes the results more readable and useful.
Answering questions: Simple vector search retrieves relevant documents or passages, but LLMs can take these results and synthesize an actual answer to the user’s question. This provides greater semantic understanding.
Linking concepts: LLMs can identify connections between disparate concepts covered across documents to provide users with a more interconnected understanding of the knowledge.
Conversational interface: An LLM can power a conversational interface for the knowledge retrieval system, allowing users to query the system using natural language questions.
With a LLM thrown into the mix, the resulting flow would look like below
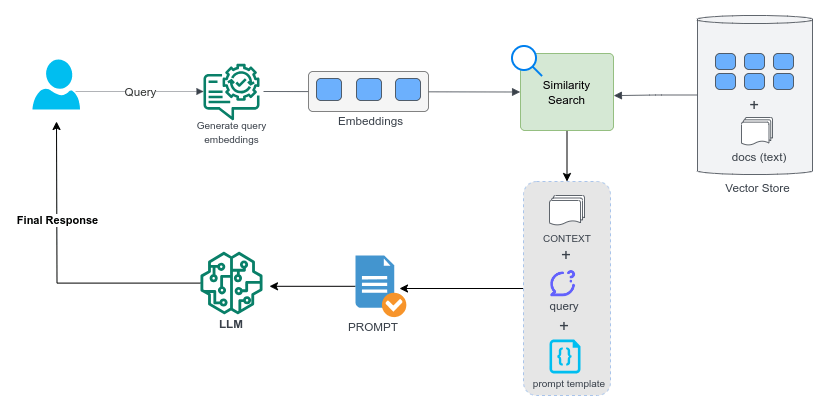
The key step in above flow is creating a good prompt template with placeholders for the Context (document snippets) and user query/question. Once the final prompt is created with righ context searched from database plus the user query, it can be sent to LLM to enable it to generate a coherent, tailored response in natural language. Below is a sample prompt template we could use
template = """Given the following extracted parts of a long document ("SOURCES") and a question ("QUESTION"), create a final answer one paragraph long.Don't try to make up an answer and use the text in the SOURCES only for the answer. If you don't know the answer, just say that you don't know.QUESTION: {question}=========SOURCES:{summaries}=========ANSWER:"""Choosing a LLM
There are many pre-trained LLMs available that could be used for enhancing our knowledge retrieval system. OpenAI is the defacto choice for most due to its capabilities but it requires a paid subscription. If you don’t want to send your data to a hosted model, llama.cpp is an excellent option that can run on consumer grade hardware. There is a python port too. llama.cpp supports a multitude of free and open source models. For the job at hand, we will use a freely available (with limits) OpenAI like API.
Enter Cohere, a canadian startup founded by one of the authors of the seminal paper that introduced the transformer architecture - Attention Is All You Need. Models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) are based on the Transformer architecture.
Cohere provides generous free tier usage of its various endpoints - embed, generate, classify, summarize, rerank. For our chatbot we will use the chat api form the cohere sdk which relies on command model. Good enough for development & testing, lets use Cohere for our completions.
Chatbot
With documents indexed and embeddings generated, we can now build a Chatbot that can harness the power of LLMs in the context of our knowledge base. Nothing enables this faster than Gradio from just your python code, without having to develop custom user interfaces spending countless hours just to test & share your machine learning apps. Below is the screengrab of our chatbot in action built using Gradio
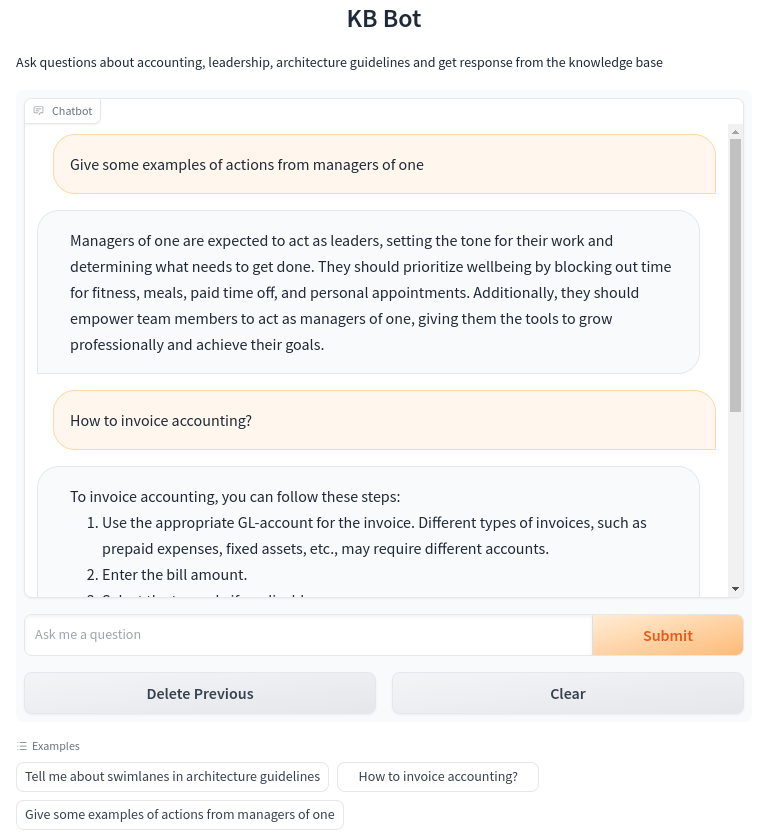
The chatbot was built using Gradio and Cohere API to power the completions. User types a question, it gets sent to Cohere along with relevant context snippets retrieved from our embeddings. Cohere generates a coherent multi-sentence response which is displayed back to the user. This is done with just a few lines of Python code, thanks to Gradio!
At the minimum Gradio needs three parameters
- The function to create a GUI for
- The desired input components (textboxes, checkboxes, dropdowns…)
- The desired output components
The fact that Gradio can generate a UI purely on a python function’s signature, makes Gradio so useful as this means ML engineers don’t need to learn UI skills to build custom user interfaces.
Gradio provides a special class for building chatbots - ChatInterface. Following is the code for our chatbot shown in above image
51 collapsed lines
import osimport chromadbfrom chromadb.utils import embedding_functionsimport constantsimport gradio as grimport coherefrom dotenv import load_dotenv
# Load environment variables from .env fileload_dotenv()persist_dir = constants.CHROMA_PERSIST_DIRcollection_name = constants.CHROMA_COLLECTION_NAMEcohere_api_key = os.getenv("COHERE_API_KEY")
cohere_client = cohere.Client(api_key=cohere_api_key)
def get_prompt_template() -> str: template = """ Given the following extracted parts of a long document ("SOURCES") and a question ("QUESTION"), create a final answer max one paragraph long. Don't try to make up an answer and use the text in the SOURCES only for the answer. If you don't know the answer, just say that you don't know. QUESTION: {question} ========= SOURCES: {summaries} ========= ANSWER: """ return template
def get_summaries_for_query(query) -> str: sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction( model_name="all-MiniLM-L12-v2" )
chroma_client = chromadb.PersistentClient(path=persist_dir) collection = chroma_client.get_collection( name=collection_name, embedding_function=sentence_transformer_ef ) # use the same embedding function that was used when docements were saved
results = collection.query(query_texts=[f"{query}"], n_results=3)
if results["documents"]: all_documents = "" for i, doc in enumerate(results["documents"]): doc_text = " ".join(doc) all_documents += doc_text + "\n\n"
return all_documents else: return "No stored response found"
def chat(query, history): history_cohere_format = [] for human, ai in history: history_cohere_format.append({human, ai})
prompt = get_prompt_template() summaries = get_summaries_for_query(query) template = get_prompt_template() prompt = template.format(question=query, summaries=summaries)
response = cohere_client.chat( message=prompt, temperature=0, # chat_history=history_cohere_format ) return response.text
chat_interface = gr.ChatInterface( chat, chatbot=gr.Chatbot(height=500), textbox=gr.Textbox(placeholder="Ask me a question", container=True, scale=7), title="KB Bot", description="Ask questions about accounting, leadership, architecture guidelines and get response from the knowledge base", theme="default", examples=[ "Tell me about swimlanes in architecture guidelines", "How to invoice accounting?", "Give some examples of actions from managers of one", ], cache_examples=True, retry_btn=None, undo_btn="Delete Previous", clear_btn="Clear",)
chat_interface.launch()Re-ranking
While vactor search responses are a good starting point, we can do better by reranking them to prepare even better context for the LLM. Cohere provides a rerank endpoint that can take in the top N search results and rerank them based on their semantic similarity to the query. Reranking is left for the reader as an exercise.
Full source code for this post is available in the associated github repo. The code is kept simple for demonstration purposes, we can use toolkits like Langchain or SemanticKernel profusely for terser, production ready code. Feel free to fork/clone and improve! Let us know if you have any other questions.
Summary
We covered a lot of ground in this post - from reviewing what embeddings are, demontrating ingestions of KB documents in a vector store (ChromaDB), building a conversational chatbot that utilizes LLMs for producing coherent, semantic responses. The goal was to democratize organizational knowledge and make it accessible to everyone in a natural way. Armed with the power of modern tools & techniques, we were able to build a knowledge retrieval system that can understand questions, retrieve relevant context and generate coherent multi-sentence responses - all with just a few lines of Python code thanks to excellent open source tools like ChromaDB, Sentence Transformers models, Cohere and Gradio.
Bonus: PostgresML, Try it out!
As a bonus we would like to call out an excellent opensource project PostgresML that offers SQL interface to machine learning algorithms. Speed is a key strength of PostgresML. If you are looking for fast & highly scalable ML services over postgres database, PostgresML is a worthy candidate. For what was covered in this article can also be implemented with PostgresML, check this out.